 번역
번역📋 목차

AI 모델이 어떻게 작동하는지 궁금하신가요? ‘AI가 스스로 배운다’는 말, 도대체 무슨 뜻일까요? 2025년 현재, 생성형 AI와 머신러닝 기술은 이미 일상과 산업을 뒤바꾸고 있어요. 하지만 그 기초 개념을 정확히 아는 사람은 많지 않아요. 🤔
이번 글에서는 머신러닝과 딥러닝의 차이부터, AI가 실제로 ‘학습’하는 전체 과정까지 차근차근 설명해드릴게요. 데이터는 어떻게 들어가고, 모델은 뭘 계산하며, 결과는 어떻게 나오는지 모든 흐름이 한눈에 정리돼요! 🧠💡
AI 개발자뿐 아니라, 기획자·마케터·교육자도 이 글 하나면 개념 이해 완전 가능! 공부가 아니라, 현실을 이해하는 도구로 AI를 알아가봐요. 🚀
🤖 머신러닝과 딥러닝의 차이

AI는 크게 머신러닝(Machine Learning)과 딥러닝(Deep Learning)으로 나뉘어요. 둘 다 데이터를 학습해 패턴을 찾는 기술이지만, 방식과 범위에서 차이가 있어요. 머신러닝은 사람이 피처(특징)를 뽑아줘야 하고, 딥러닝은 스스로 피처를 학습하는 신경망 구조를 사용해요. 🧠
예를 들어 이메일 스팸 필터링을 머신러닝으로 만들면, ‘특정 단어 포함’, ‘보낸 시간’, ‘링크 수’ 같은 피처를 사람이 설정해줘야 해요. 하지만 딥러닝은 이메일 본문을 통째로 받아들이고 자체적으로 중요한 특징을 학습해서 결과를 내요. 📨
머신러닝은 규칙 기반의 학습에 강하고, 딥러닝은 이미지, 음성, 자연어처럼 구조가 복잡한 데이터를 잘 처리해요. 그래서 오늘날의 생성형 AI는 대부분 딥러닝 기반이에요. 🎨🗣️
🤖 머신러닝 vs 딥러닝 비교표
| 항목 | 머신러닝 | 딥러닝 |
|---|---|---|
| 데이터 처리 | 사람이 특징 추출 | 자동으로 특징 학습 |
| 학습 구조 | 선형회귀, SVM 등 | 다층 신경망(Neural Net) |
| 적합 데이터 | 정형 데이터 | 비정형 데이터(이미지, 음성 등) |
| 계산량 | 상대적으로 적음 | 높고 GPU 필요 |
머신러닝은 시작을 쉽게 해주고, 딥러닝은 스케일 업과 자동화를 가능하게 해줘요. 둘 다 AI 학습의 큰 기둥이기 때문에 함께 이해하는 게 좋아요! 🏗️
🧠 AI가 배우는 원리: 모델 학습 구조

AI 모델은 수학적으로 말하면 입력(X)을 받아 출력(Y)을 예측하는 함수예요. 이 함수는 학습을 통해 스스로 형태를 바꿔가며 점점 더 정답에 가까워져요. 그걸 우리는 모델 학습이라고 부르는 거예요! 🤯
AI는 단순한 공식이 아니라 수천, 수만 개의 가중치(parameter)로 구성된 ‘모델’이라는 복잡한 계산 시스템을 통해 학습해요. 이 모델은 입력값을 받아 내부 계산을 통해 출력을 생성하고, 그 출력이 얼마나 정답과 다른지를 오차 함수(loss function)로 판단하죠. ⚖️
그 다음, 오차를 줄이기 위해 가중치를 조정하는 과정을 반복하는데, 이 과정을 역전파(backpropagation)와 경사하강법(gradient descent)이라고 해요. 결국, AI 학습이란 건 ‘정답과의 차이를 줄여가는 과정’이에요. 🎯
🧠 AI 모델 학습 과정 요약표
| 구성 요소 | 설명 | 역할 |
|---|---|---|
| 입력 (X) | 이미지, 텍스트 등 학습 데이터 | 예측 시작점 |
| 모델 (f) | 수많은 파라미터를 가진 함수 | 예측 수행 |
| 출력 (Y′) | AI가 만든 결과값 | 실제 정답과 비교됨 |
| 손실 함수 (Loss) | 오차 계산 공식 | 얼마나 틀렸는지 측정 |
| 최적화 (Optimization) | 오차 줄이기 위한 파라미터 조정 | 정답에 가까워짐 |
이 과정을 데이터 수천~수백만 개에 대해 반복하면서 AI는 점점 더 정확한 예측을 하게 돼요. 그러니까 AI는 ‘기계’지만, 데이터를 통해 스스로 발전하는 존재인 셈이에요. 🤖📈
📊 학습 데이터란 무엇인가요?

AI가 똑똑해지려면 '배우는 재료'가 필요해요. 바로 그 재료가 학습 데이터예요. AI는 스스로 생각하는 게 아니라, 주어진 데이터를 바탕으로 규칙을 익히는 것이죠. 그래서 AI의 수준은 결국 데이터의 질과 양에 따라 결정돼요. 📚
예를 들어, 고양이 사진을 보여주며 "이건 고양이야"라고 알려주는 게 학습 데이터예요. 그런 이미지가 수천 장 쌓이면 AI는 '고양이의 특징'을 스스로 알아차릴 수 있어요. 즉, 입력(X) + 정답(Y) 형태의 셋트가 AI 학습의 기본이에요. 🐱📷
텍스트, 이미지, 음성, 숫자 등 다양한 형태의 데이터가 존재해요. 하지만 AI가 이해하기 쉽게 만들기 위해선 일관된 구조, 정제된 형식이 필요해요. 그래서 데이터 전처리가 AI 성능에 큰 영향을 주는 거예요. 🧹🧠
📊 학습 데이터 유형 정리표
| 유형 | 설명 | 예시 |
|---|---|---|
| 정형 데이터 | 표처럼 구조화된 데이터 | 엑셀, DB 테이블 |
| 비정형 데이터 | 자유 형식의 데이터 | 이미지, 텍스트, 음성 |
| 라벨링 데이터 | 정답이 붙어 있는 데이터 | ‘개’라고 표시된 강아지 사진 |
| 시계열 데이터 | 시간 순으로 변화하는 값 | 주가, 날씨, 센서 기록 |
학습 데이터는 AI의 ‘교과서’라고 할 수 있어요. 이 교과서가 얼마나 다양하고, 정확하며, 정리되어 있는지에 따라 AI의 사고력과 이해도가 달라져요. 데이터가 좋아야 AI도 진짜 ‘현명한 판단’을 할 수 있는 거예요! 🤓📈
🔁 훈련, 검증, 테스트의 역할

AI가 배우는 과정은 ‘한 덩어리 데이터’로 끝나지 않아요. 모델이 진짜 잘 학습됐는지 확인하기 위해, 데이터는 세 가지로 나눠서 사용해요. 이걸 Train / Validation / Test라고 불러요. 각각의 역할이 다르기 때문에 꼭 구분해서 이해해야 해요! 🧠
1. 훈련 데이터 (Training Set)는 말 그대로 AI가 배우는 데 쓰이는 자료예요. 입력과 정답이 같이 있어서 AI가 패턴을 학습하고, 파라미터를 조정하는 데 사용돼요. 모델이 처음부터 끝까지 훈련받는 곳이죠. 💪
2. 검증 데이터 (Validation Set)는 훈련 도중, 모델이 얼마나 일반화됐는지 평가하는 데 써요. 훈련 데이터엔 익숙하지만, 처음 보는 검증 데이터에서도 잘 맞춰야 좋은 모델이에요. 이때 성능이 떨어지면 ‘과적합’이 발생한 걸로 봐요. 📉
3. 테스트 데이터 (Test Set)는 훈련과 검증이 끝난 뒤 최종 평가를 위한 전혀 새로운 데이터예요. 이건 마치 ‘시험 문제’ 같은 거예요. 여기서 성능이 좋아야 실제 현장에서 잘 작동할 수 있는 모델이라고 인정받아요. 🎯
🔁 Train / Validation / Test 비교표
| 구분 | 사용 시점 | 목적 | 결과 활용 |
|---|---|---|---|
| 훈련 데이터 | 모델 학습 시 | 가중치 조정 | 모델 훈련 |
| 검증 데이터 | 훈련 중간 | 모델 평가 및 튜닝 | 하이퍼파라미터 조정 |
| 테스트 데이터 | 훈련 후 | 최종 성능 측정 | 모델 검증 |
이 세 가지 데이터를 잘 나눠 쓰면 AI가 과적합 없이 진짜 실력을 갖추게 돼요. 학습의 흐름을 잘 이해하면, 모델 튜닝과 평가도 훨씬 쉬워져요! 🎓🔧
📈 과적합 vs 일반화 쉽게 이해하기
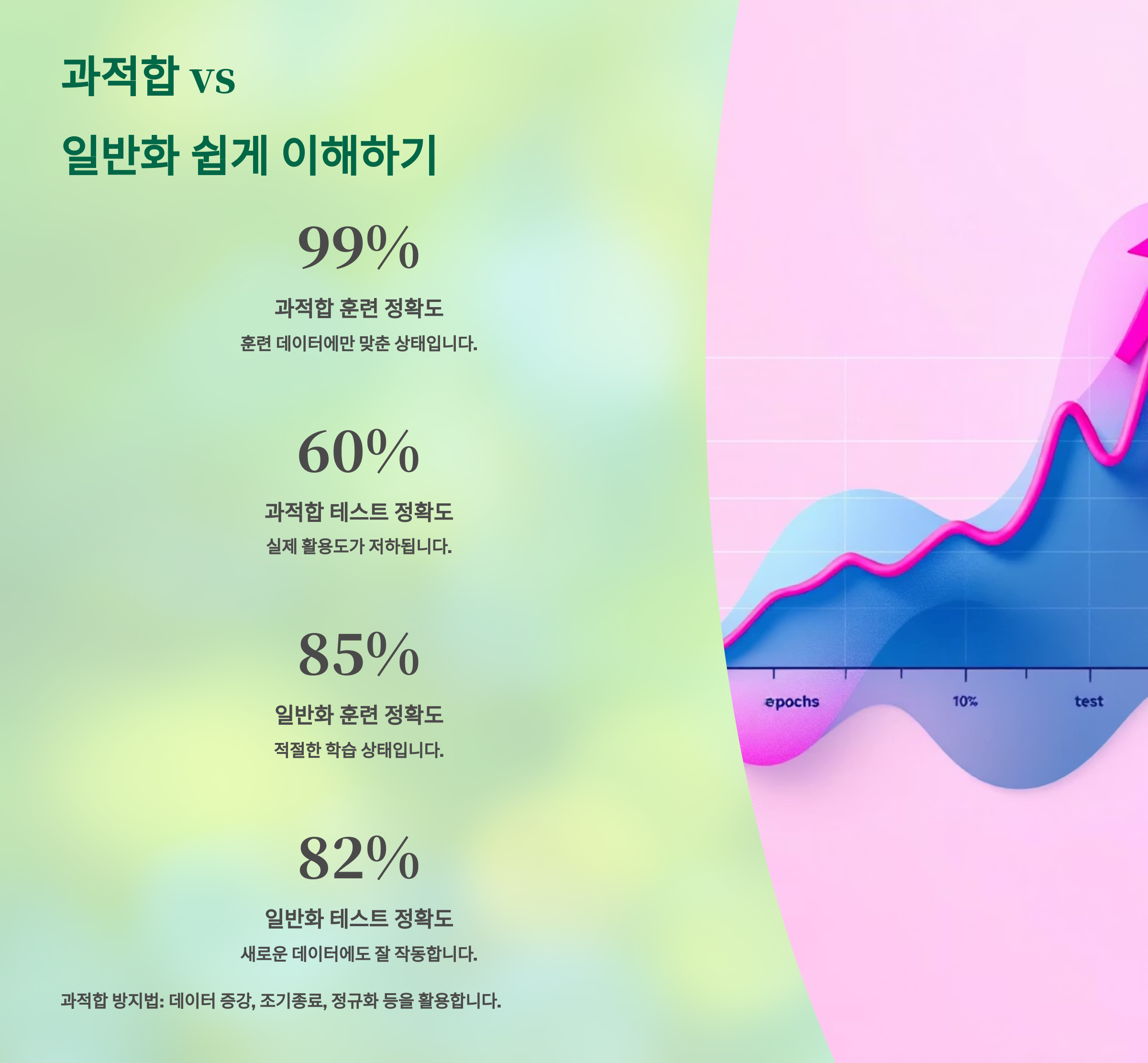
AI 모델이 너무 똑똑하면 문제일 수도 있다는 사실, 알고 계셨나요? 학습 데이터를 너무 잘 외우면 오히려 새로운 데이터에서 성능이 떨어져요. 이걸 ‘과적합’이라고 해요. 반면, 익힌 걸 바탕으로 처음 보는 문제도 잘 풀면 ‘일반화’가 잘됐다고 해요. 🧠💡
예를 들어 학생이 모의고사 문제만 100번 풀어서 만점을 받아도, 수능에서 낯선 문제가 나오면 못 풀 수 있죠? 그게 과적합이에요. AI도 비슷하게, 훈련 데이터에만 최적화되면 실전에서 약한 모델이 돼요. 😓
일반화란, 학습한 내용을 바탕으로 처음 보는 데이터에서도 정확하게 예측할 수 있는 능력이에요. AI가 현실에서 잘 작동하려면, 무조건 일반화가 잘돼야 해요! 🌍
📈 과적합 vs 일반화 비교표
| 항목 | 과적합 | 일반화 |
|---|---|---|
| 정의 | 훈련 데이터에만 과하게 맞춘 상태 | 새로운 데이터에도 잘 맞는 상태 |
| 모양 | 복잡한 모델곡선 | 매끄럽고 단순한 모델 |
| 결과 | 훈련은 완벽, 실제 성능은 낮음 | 훈련·테스트 모두 일정한 성능 |
| 해결법 | 정규화, dropout, 더 많은 데이터 | 훈련·검증 분리, 성능 균형 |
AI는 마치 공부 잘하는 학생처럼 암기형이 아니라 응용형이 되어야 해요. 그걸 결정하는 핵심 개념이 바로 ‘과적합을 줄이고, 일반화를 높이는 것’이에요! 🧑🏫✨
🔧 하이퍼파라미터란 무엇인가요?

AI 모델이 똑똑해지려면 단순히 데이터만 많다고 되는 게 아니에요. 학습 속도, 반복 횟수, 층 개수, 노드 수 같은 요소들이 모두 모델 성능을 결정하는 변수예요. 이걸 바로 ‘하이퍼파라미터’라고 불러요! 🎛️
하이퍼파라미터는 사람이 직접 설정하는 값이에요. 모델 내부에서 자동으로 조정되는 파라미터와는 다르죠. 설정이 너무 작으면 학습이 느리고, 너무 크면 과적합이 발생할 수 있어요. 딱 적절한 밸런스를 찾는 게 중요해요. 🧠⚖️
하이퍼파라미터 튜닝은 AI 개발자들이 가장 많은 시간을 쓰는 작업 중 하나예요. 성능 향상을 위해 수십~수백 번 실험하는 경우도 많아요! 🧪💻
🔧 주요 하이퍼파라미터 정리표
| 이름 | 역할 | 추천값 예시 |
|---|---|---|
| Learning Rate | 학습 속도 조절 | 0.001 ~ 0.01 |
| Epoch | 전체 데이터 반복 학습 횟수 | 10 ~ 100 |
| Batch Size | 한 번에 학습할 데이터 개수 | 16, 32, 64 |
| Hidden Layers | 중간 계산 단계 개수 | 2~5개 정도 |
| Dropout Rate | 과적합 방지를 위한 무작위 연결 차단 비율 | 0.2 ~ 0.5 |
하이퍼파라미터는 AI 학습의 온도조절기 같은 거예요. 적절한 설정은 모델 성능을 몇 배 이상 끌어올릴 수 있어요. AI를 ‘조율한다’는 감각, 하이퍼파라미터로 키워보세요! 🎯📊
🧪 실전 학습 프로세스 단계별 정리

AI 학습은 단순히 ‘데이터 넣고 결과 확인’이 아니에요. 모델 설계 → 데이터 준비 → 훈련 → 평가 → 개선까지 여러 단계가 연결된 프로세스로 구성돼 있어요. 이 흐름을 제대로 이해해야 실제 프로젝트도 성공할 수 있어요! 🔄💻
각 단계를 이해하면 어디서 성능이 떨어졌는지, 무엇을 조정해야 하는지 스스로 판단할 수 있어요. 그게 바로 AI 활용의 실전 역량이에요! 💡
🧪 AI 학습 단계 요약표
| 단계 | 설명 | 실전 팁 |
|---|---|---|
| 1. 문제 정의 | 무엇을 예측/분류/생성할지 정함 | 정확한 목표 설정이 핵심 |
| 2. 데이터 수집 | 입력값과 정답 데이터 모으기 | 공공 데이터, 크롤링, API 활용 |
| 3. 전처리 | 결측치 제거, 정규화, 라벨링 등 | 깨끗한 데이터가 성능 좌우 |
| 4. 모델 설계 | 기계학습 or 딥러닝 모델 선택 | 간단한 모델부터 시작! |
| 5. 학습/훈련 | 데이터로 모델을 학습시킴 | 검증 데이터로 과적합 점검 |
| 6. 평가 | 테스트 데이터로 최종 성능 측정 | 정확도, F1 score 등 지표 확인 |
| 7. 개선/재훈련 | 오차 분석 후 튜닝 또는 재학습 | 하이퍼파라미터 조정, 더 많은 데이터 활용 |
이 7단계를 이해하면, AI 모델을 그저 사용하는 사람에서 설계하고 판단하는 사람으로 바뀔 수 있어요. 이제 당신도 학습의 흐름을 아는 진짜 AI 유저! 🎓🧠
❓ FAQ

Q1. AI 모델을 학습시키는 데 얼마나 시간이 걸리나요?
A1. 모델 크기, 데이터 양, 하드웨어 성능에 따라 달라요. 간단한 모델은 몇 분, 대형 모델은 수일~수주 걸릴 수 있어요. ⏱️
Q2. 데이터가 적으면 AI 학습이 불가능한가요?
A2. 꼭 그렇진 않아요. 전이학습(transfer learning)이나 데이터 증강 기법을 사용하면 작은 데이터로도 충분히 학습 가능해요. 📦
Q3. 하이퍼파라미터는 무조건 조정해야 하나요?
A3. 기본값으로도 어느 정도 학습은 되지만, 튜닝을 통해 성능이 훨씬 향상될 수 있어요. 그래서 보통 여러 조합을 실험해봐요. 🔧
Q4. 과적합이 발생했는지 어떻게 알 수 있나요?
A4. 훈련 성능은 높은데, 검증/테스트 성능은 낮다면 과적합이 의심돼요. 그래프나 지표로 비교해보면 바로 확인돼요. 📉
Q5. 학습이 실패했을 때는 어떤 걸 먼저 확인해야 하나요?
A5. 데이터 품질, 전처리 상태, 모델 구조, 손실 함수 설정 등을 점검해보세요. 대부분은 데이터 문제에서 시작돼요. 🔍
Q6. 모델 평가 지표는 어떤 걸 써야 하나요?
A6. 분류는 정확도, 정밀도, F1-score, 회귀는 MSE, MAE, R2 등을 사용해요. 목표에 따라 적절한 지표를 선택해야 해요. 📊
Q7. 좋은 데이터는 어떤 데이터인가요?
A7. 정확하고 일관성 있으며, 라벨이 명확한 데이터가 좋아요. 노이즈가 적고, 다양한 상황을 포함한 데이터가 가장 이상적이에요. 🧼
Q8. 학습 데이터를 공개적으로 구할 수 있나요?
A8. 네! Kaggle, Hugging Face, UCI ML Repository 등 다양한 사이트에서 고품질 데이터를 무료로 얻을 수 있어요. 🌐📥
✅ 마무리

AI는 마법이 아니에요. 그저 엄청나게 많은 수학과 데이터, 반복 학습으로 이루어진 복잡하지만 논리적인 도구일 뿐이에요. 그리고 그 핵심은 바로 ‘학습’이에요. 📚
이번 글에서는 머신러닝과 딥러닝의 차이부터 모델 학습 구조, 데이터 개념, 과적합, 하이퍼파라미터, 실전 프로세스까지 AI가 어떻게 배우는지 전 과정을 쉽게 정리했어요. 기초 개념을 탄탄히 알면, 어떤 최신 기술도 훨씬 빠르게 이해할 수 있어요. 🚀
제가 생각했을 때 AI 학습의 본질은 “데이터에서 의미를 찾고, 더 나은 판단을 배우는 과정”이에요. 우리 인간이 공부하는 과정과 크게 다르지 않죠. 그래서 AI를 이해하는 건 결국 ‘학습’에 대해 다시 생각해보는 일이기도 해요. 🔍
여기까지 읽은 당신은 이미 AI 기술을 바라보는 눈이 한 단계 올라간 사람이에요. 이제 용어에 휘둘리지 않고, 본질을 꿰뚫는 관점으로 AI를 바라볼 수 있어요. 다음엔 실전 모델 튜닝도 도전해보세요! 💪🤖
'코딩 입문자' 카테고리의 다른 글
| 💻 직장인 코딩 독학, 퇴근 후 1시간 투자로 연봉 바꾼 실전 루틴 (0) | 2025.05.09 |
|---|---|
| 💻 퇴근 후 3개월 투자로 연봉이 달라집니다 – 성인 코딩학원 TOP5 (0) | 2025.05.08 |
| 🤖 2025 생성형 AI 완벽 해설! 개념·활용사례·장단점·직장·교육 현장 적용법 총정리 (0) | 2025.05.06 |
| 🤖 2025 챗GPT 교육 활용법 총정리! 수업 준비부터 자기주도 학습까지 실전 적용 가이드 (0) | 2025.05.05 |
| 🧠 2025 딥러닝이란? 개념부터 활용 분야까지 한눈에 이해하는 AI 입문 가이드 (0) | 2025.05.04 |



